| 例 |
| 正規表現の例 |
| 数値範囲 |
| 浮動小数点数 |
| メールアドレス |
| IPアドレス |
| 有効な日付 |
| 数値の日付をテキストに変換 |
| クレジットカード番号 |
| 行全体にマッチ |
| 重複する行の削除 |
| プログラミング |
| 近接した2つの単語 |
| 落とし穴 |
| 壊滅的なバックトラッキング |
| 過剰な繰り返し |
| サービス拒否 |
| すべてをオプションにする |
| 繰り返しキャプチャグループ |
| Unicodeと8ビットの混合 |
| このサイトの詳細 |
| はじめに |
| 正規表現クイックスタート |
| 正規表現チュートリアル |
| 置換文字列チュートリアル |
| アプリケーションとプログラミング言語 |
| 正規表現の例 |
| 正規表現リファレンス |
| 置換文字列リファレンス |
| 書籍レビュー |
| 印刷可能なPDF |
| このサイトについて |
| RSSフィード&ブログ |

暴走する正規表現:壊滅的なバックトラッキング
次の正規表現を考えてみましょう(x+x+)+y。この作為的な例は、次のように記述されるべきだと叫び出す前にxx+yまたはx{2,}yと、ひどくネストした数量子なしで全く同じにマッチすることを:各「x」がより複雑な何かを表し、特定の文字列が両方の「x」にマッチすると仮定してください。実際の例については、下記のHTMLファイルのセクションを参照してください。
この正規表現をxxxxxxxxxyに適用するとどうなるかを見てみましょう。最初のx+は10個すべてのxの文字にマッチします。2番目のx+は失敗します。最初のx+は9つの一致にバックトラックし、2番目のものが残りのxを取得します。グループはこれで一度一致しました。グループは繰り返しますが、最初のx+で失敗します。1回の繰り返しで十分だったので、グループはマッチします。yがマッチしy、全体的なマッチが見つかります。正規表現が機能すると宣言され、コードが顧客に出荷され、彼のコンピュータは爆発します。ほとんど。
上記の正規表現は、対象の文字列にyがないと、醜くなります。 yが失敗すると、正規表現エンジンはバックトラックします。グループにはバックトラックできる反復が1つあります。2番目のx+は1つのxにしか一致しなかったので、バックトラックできません。しかし、最初のx+は1つのxを諦めることができます。2番目のx+はすぐにxxにマッチします。グループには再び反復が1つあり、次の反復に失敗し、yが失敗します。再びバックトラックすると、2番目のx+にはバックトラックできる位置が1つあり、マッチをxに減らします。グループは2回目の反復を試みます。最初のx+はマッチしますが、2番目は文字列の末尾で動けなくなります。再びバックトラックすると、グループの最初の反復の最初のx+は7文字に減ります。2番目のx+がマッチしxxxに失敗しy、2番目のx+はxxに減らされ、そしてxに減らされます。さて、グループは2回目の反復に一致することができます。各xに対して1つx+で。しかし、この(7,1),(1,1)の組み合わせも失敗します。したがって、(6,4)に移動し、次に(6,2)(1,1)に移動し、次に(6,1),(2,1)に移動し、次に(6,1),(1,2)に移動します。これで、流れを理解し始めたと思います。
RegexBuddyのデバッガーで10xの文字列に対してこの正規表現を試すと、最終的なyがないことを把握するのに2558ステップかかります。11xの文字列の場合、5118ステップが必要です。12の場合、10238ステップかかります。明らかに、ここではO(2^n)の指数複雑性があります。19xでは、100万ステップ以上を表示できないため、デバッガーは終了します。
RegexBuddyは、円運動をしていることを検出してマッチの試行を中止するため、寛容です。他の正規表現エンジン(.NETなど)は永遠に継続し、他のエンジン(バージョン5.10より前のPerlなど)はスタックオーバーフローでクラッシュします。スタックオーバーフローは、アプリケーションが痕跡や説明なしに消えてしまう傾向があるため、Windowsでは特に厄介です。ユーザーが独自の正規表現を提供できるWebサービスを実行する場合は、非常に注意してください。正規表現の経験が少ない人は、指数関数的に複雑な正規表現を思いつく驚くべきスキルを持っています。
所有数量詞とアトミックグループによる救済
上記の例では、正気なのは、明らかにそれをxx+yとして書き直して、ネストされた数量詞を完全に排除することです。ネストされた数量詞は、それ自体が繰り返されるか、または代替されるグループ内で繰り返されるまたは代替されるトークンです。これらはほとんど常に壊滅的なバックトラックにつながります。それらがバックトラックしない唯一の状況は、グループ内の各代替の開始がオプションではなく、他のすべての代替の開始と相互に排他的であり、それに続くトークンと相互に排他的である場合(グループ内の代替内)です。例えば(a+b+|c+d+)+yは安全です。何かが失敗した場合、正規表現エンジンは正規表現全体をバックトラックしますが、直線的にバックトラックします。その理由は、すべてのトークンが相互に排他的であるからです。それらのいずれも、他のいずれかによって一致した文字に一致することはできません。したがって、各バックトラック位置での一致の試行は失敗し、正規表現エンジンは直線的にバックトラックします。これをaaaabbbbccccddddでテストすると、RegexBuddyは、それを把握するのに数百万ステップではなく、わずか13ステップしか必要としません。
ただし、すべてを相互に排他的にするように正規表現を書き換えることが常に可能または簡単であるとは限りません。したがって、正規表現エンジンにバックトラックしないように指示する方法が必要です。すべてのxを取得したら、バックトラックする必要はありません。いずれかのyによって一致したものには、x+は存在しない可能性があります。所有数量詞を使用すると、正規表現は次のようになります。(x+x+)++y。これにより、21xの文字列はわずか7ステップで失敗します。これは、すべてのxに一致するのに6ステップ、yが失敗することを把握するのに1ステップです。バックトラックはほとんど行われません。アトミックグループを使用すると、正規表現は次のようになります。(?>(x+x+)+)yであり、まったく同じ結果になります。
実例:CSVレコードのマッチング
これは、私がかつて扱った技術サポート事例からの実例です。顧客は、カンマ区切りのテキストファイルで、行の12番目の項目がPで始まる行を見つけようとしていました。彼は、罪のないように見える正規表現^(.*?,){11}P.
を使用していました。一見すると、この正規表現は適切に機能するはずのように見えます。遅延ドットとカンマは、単一のカンマ区切りのフィールドに一致し、{11}は最初の11フィールドをスキップします。最後に、Pは12番目のフィールドが実際にPで始まるかどうかをチェックします。実際、これは12番目のフィールドが実際にPで始まる場合にまさに起こることです。
問題は、12番目のフィールドがPで始まらない場合に表面化します。文字列が1,2,3,4,5,6,7,8,9,10,11,12,13だとしましょう。その時点で、正規表現エンジンはバックトラックします。それは^(.*?,){11}が1,2,3,4,5,6,7,8,9,10,11を消費した時点までバックトラックし、カンマの最後の一致を諦めます。次のトークンは再びドットです。ドットはカンマにマッチします。ドットはカンマにマッチします!ただし、カンマは12番目のフィールドの1と一致しないため、ドットは.*?,の11回目の反復が11,12,を消費するまで続きます。問題の根本がすでにわかります。フィールドの内容と一致する正規表現の部分(ドット)は、区切り文字(カンマ)にも一致します。二重の繰り返し({11}内のアスタリスク)のため、これは壊滅的な量のバックトラックにつながります。
正規表現エンジンは、13番目のフィールドがPで始まるかどうかを確認します。そうではありません。13番目のフィールドの後にカンマがないため、正規表現エンジンは.*?,の11回目の反復に一致できなくなります。しかし、そこで諦めることはありません。それは10回目の反復にバックトラックし、10回目の反復の一致を10,11,に拡張します。まだPがないため、10回目の反復は10,11,12,に拡張されます。再び文字列の末尾に到達すると、9回目の反復で同じストーリーが始まり、続いて9,10,, 9,10,11,, 9,10,11,12,に拡張されます。しかし、各拡張の間には、試行される可能性がさらにあります。9回目の反復が9,10,を消費すると、10回目は11,だけでなく11,12,にも一致する可能性があります。継続的に失敗すると、エンジンは8回目の反復にバックトラックし、9回目、10回目、11回目の反復ですべて可能な組み合わせを試みます。
理解できると思います。12番目のフィールドがPで始まらない各行に対して、正規表現エンジンが試行する可能性のある組み合わせの数は膨大です。ほとんどの行の12番目のフィールドの先頭にPがない大きなCSVファイルでこの正規表現を実行すると、これらすべてに時間がかかります。
壊滅的なバックトラックの防止
解決策は簡単です。繰り返し演算子をネストするときは、同じマッチにマッチする方法が1つしかないことを絶対に確認してください。内側のループを4回、外側のループを7回繰り返すと、内側のループを6回、外側のループを2回繰り返すのと同じ全体的な一致になる場合は、正規表現エンジンがそれらの組み合わせをすべて試すことを確信できます。
私たちの例では、マッチさせたいものをより正確にすることが解決策となります。11個のカンマ区切りのフィールドをマッチさせたいとします。フィールドにはカンマを含めてはなりません。したがって、正規表現は次のようになります。^([^,\r\n]*,){11}P。もしPが見つからない場合でも、エンジンはバックトラックします。しかし、バックトラックは11回だけであり、毎回[^,\r\n]はカンマを超えて拡張することができず、正規表現エンジンは追加のオプションを試すことなく、11回の反復のうち前の1回にすぐに戻ります。
RegexBuddyとの違いを見る
RegexBuddyのデバッガーでこの例を試すと、元の正規表現は^(.*?,){11}Pマッチしないと結論付けるまでに25,593ステップを必要とすることがわかります。1,2,3,4,5,6,7,8,9,10,11,12もし文字列が1,2,3,4,5,6,7,8,9,10,11,12,13、さらに3文字多いと、ステップ数は52,149に倍増します。この種の指数関数的な速度で、長い行を含む大きなファイルでこの正規表現を試みることは、永遠に時間がかかる可能性があると想像するのは難しくありません。
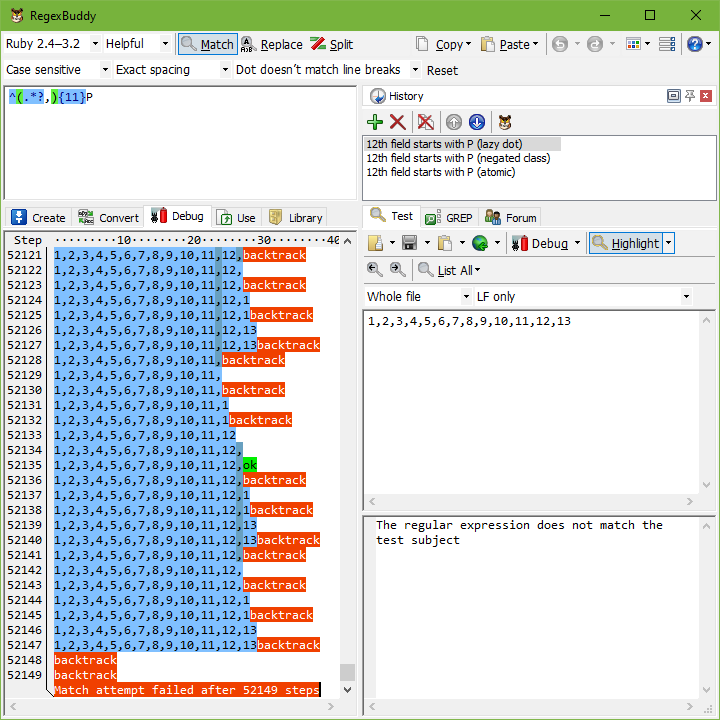
改善された正規表現は^([^,\r\n]*,){11}Pしかし、対象文字列に12個の数字があろうと、13個の数字があろうと、16個の数字があろうと、10億個の数字があろうと、失敗するまでにわずか52ステップしか必要としません。元の正規表現の複雑さが指数関数的であったのに対し、改善された正規表現の複雑さは、11番目のフィールドに続くものに関係なく一定です。その理由は、正規表現が12番目のフィールドがPで始まらないことを発見すると、ほぼすぐに失敗するからです。グループの11回の反復を、再度拡張することなくバックトラックします。
改善された正規表現の複雑さは、最初の11個のフィールドの長さに比例して線形です。例では、11個のフィールドをマッチさせるには24ステップが必要です。Pをマッチさせることができないと発見するのに1ステップしかかかりません。その後、2つの量指定子のすべての反復をバックトラックするためにさらに27ステップが必要です。エンジンは12番目のフィールドがどこから始まるかを見つけるために、最初の11個のフィールドのすべての文字をスキャンする必要があるため、これが最善です。改善された正規表現は完璧な解決策です。
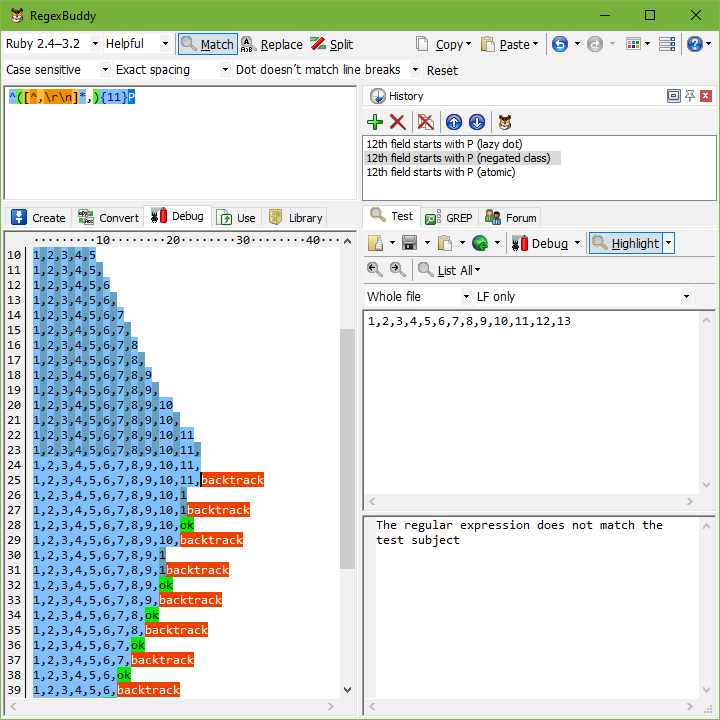
アトミックグループを使用した代替ソリューション
上記の例では、目的をより適切に指定することで、バックトラックの量を非常に低いレベルに簡単に減らすことができました。しかし、それが常にこのように単純に可能であるとは限りません。その場合は、正規表現エンジンがバックトラックするのを防ぐためにアトミックグループを使用する必要があります。
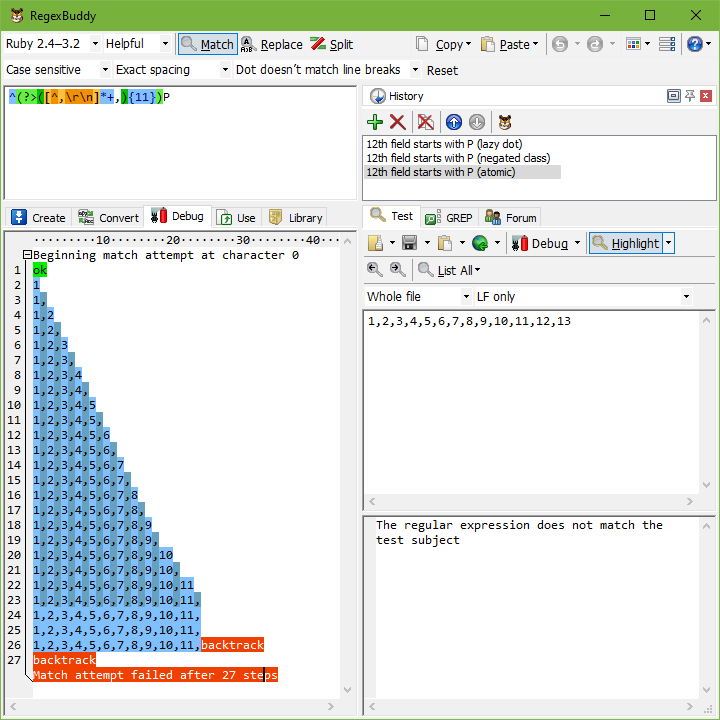
アトミックグループを使用すると、上記の正規表現は次のようになります。^(?>(.*?,){11})P。間のすべては(?>)、正規表現エンジンがグループを離れると、正規表現エンジンによって1つの単一のトークンとして扱われます。グループ全体が1つのトークンであるため、正規表現エンジンがグループに一致するものを見つけると、バックトラックは発生しません。バックトラックが必要な場合、エンジンはグループの前にある正規表現トークン(この例ではキャレット)までバックトラックする必要があります。グループの前にトークンがない場合、正規表現は文字列内の次の位置で正規表現全体を再試行する必要があります。
次の方法を見てみましょう^(?>(.*?,){11})Pに適用されます1,2,3,4,5,6,7,8,9,10,11,12,13。キャレットは文字列の先頭で一致し、エンジンはアトミックグループに入ります。アスタリスクは遅延であるため、ドットは最初はスキップされます。しかし、カンマは一致しない1ので、エンジンはドットにバックトラックします。そうです。ここではバックトラックが許可されています。アスタリスクは所有格ではなく、アトミックグループですぐに囲まれていません。つまり、正規表現エンジンはアトミックグループの閉じ括弧を横切っていません。ドットは一致する1、カンマも一致します。{11}は、アトミックグループがマッチするまでさらに繰り返しを引き起こします1,2,3,4,5,6,7,8,9,10,11,.
さて、エンジンはアトミックグループを離れます。グループはアトミックであるため、すべてのバックトラック情報が破棄され、グループは単一のトークンと見なされるようになりました。エンジンは次に一致させようとしますPから112番目のフィールドで。これは失敗します。
これまでのところ、すべてが元の厄介な正規表現と同じように発生しました。ここで違いが出てきます。Pが一致しないため、エンジンはバックトラックします。しかし、アトミックグループはすべてのバックトラック位置を忘れさせました。文字列の先頭での一致試行はすぐに失敗します。
これが、アトミックグループと所有格量指定子の目的です。バックトラックを許可しないことによる効率化です。この問題に対する最も効率的な正規表現は次のとおりです。^(?>((?>[^,\r\n]*),){11})P所有格で貪欲なアスタリスクの繰り返しは、バックトラックする遅延ドットよりも高速であるためです。所有格量指定子が使用可能な場合は、次のように記述して煩雑さを軽減できます。^(?>([^,\r\n]*+,){11})P.
RegexBuddyのデバッガーで最終的なソリューションをテストすると、11個のフィールドをマッチさせるために同じ24ステップが必要であることがわかります。次に、アトミックグループを終了してすべてのバックトラック情報を破棄するのに1ステップかかります。Pを一致させることができないことを発見するのに、やはり1ステップかかります。しかし、アトミックグループのため、すべてをバックトラックするのに1ステップしかかかりません。
完全なHTMLファイルをすばやくマッチングする
壊滅的なバックトラックが発生するもう1つの一般的な状況は、「何か」の後に「何でも」が続き、「別の何か」の後に「何でも」が続くものをマッチさせようとする場合で、遅延ドット.*?が使用されています。「何でも」が多ければ多いほど、バックトラックが増えます。場合によっては、遅延ドットは単に怠惰なプログラマーの兆候です。".*?"は、引用符の間で何かを許可したくないため、二重引用符で囲まれた文字列をマッチさせるのには適切ではありません。文字列に(エスケープされていない)埋め込み引用符を含めることはできないため、"[^"\r\n]*"の方が適切であり、より大きな正規表現に組み合わせても壊滅的なバックトラックを引き起こすことはありません。ただし、場合によっては「何でも」は本当にそのとおりです。問題は、「別の何か」も「何でも」として適格であるため、本当のx+x+状況になります。
正規表現を使用して完全なHTMLファイルに一致させ、ファイルから基本的な部分を抽出するとします。HTMLファイルの構造がわかっていれば、正規表現を記述するのは非常に簡単です。<html>.*?<head>.*?<title>.*?</title>.*?</head>.*?<body[^>]*>.*?</body>.*?</html>。「ドットが改行に一致する」または「単一行」マッチングモードがオンになっている場合、有効なHTMLファイルでは正常に動作します。
残念ながら、この正規表現は、一部のタグが欠落しているHTMLファイルではほとんど機能しません。最悪のケースは、ファイルの末尾に</html>タグがない場合です。いつ</html>が一致しない場合、正規表現エンジンはバックトラックし、次のマッチを諦めます</body>.*?。次に、</body>の前の遅延ドットをさらに拡張し、2番目の終了</body>タグをHTMLファイル内で探します。それが失敗すると、エンジンは<body[^>]*>.*?を諦め、2番目の開始<body[^>]*>タグをファイルの最後まで探し始めます。それも失敗するため、エンジンは、ファイルの最後まで2番目の終了ヘッドタグ、2番目の終了タイトルタグなどを探して続行します。
RegexBuddyのデバッガーでこの正規表現を実行すると、出力はのこぎりの歯のように見えます。正規表現はファイル全体に一致し、少しバックアップし、ファイル全体に再度一致し、さらにバックアップし、さらにバックアップし、再びすべてに一致するなど、7つの各.*?トークンがファイルの最後に到達するまで行われます。結果として、この正規表現の最悪の場合の複雑さはN^7になります。末尾にテキストを追加して、<html>タグが欠落しているHTMLファイルの長さを2倍にすると、正規表現はHTMLファイルが無効であると判断するのに128倍(2^7)の時間がかかります。これは、最初の例の2^Nの複雑さほど壊滅的ではありませんが、大きな無効なファイルでは非常に許容できないパフォーマンスにつながります。
この状況では、正規表現におけるリテラルテキストブロック(区切り文字として機能するHTMLタグ)は、有効なHTMLファイル内でそれぞれ一度しか出現しないことがわかっています。そのため、遅延ドット(区切られたコンテンツ)をそれぞれアトミックグループにパッケージ化することが非常に簡単になります。
<html>(?>.*?<head>)(?>.*?<title>)(?>.*?</title>)(?>.*?</head>)(?>.*?<body[^>]*>)
(?>.*?</body>).*?</html>は、元の正規表現と同じステップ数で有効なHTMLファイルにマッチします。利点は、無効なHTMLファイルでは、有効なHTMLファイルにマッチするのとほぼ同じ速さで失敗することです。もし</html>マッチに失敗すると、正規表現エンジンはバックトラックし、最後の遅延ドットのマッチを諦めます。しかし、その後、バックトラックするものがなくなります。遅延ドットはすべてアトミックグループ内にあるため、正規表現エンジンはバックトラック位置を破棄しています。これらのグループは「それ以上展開しない」という障害物として機能します。正規表現エンジンは、即座に失敗を宣言せざるを得なくなります。
各アトミックグループには、遅延ドットの後にHTMLタグも含まれていることに気づかれたでしょう。これは非常に重要です。遅延ドットが、対応するHTMLタグが見つかるまでバックトラックすることを許可しています。例えば、.*?</body>が処理しているときLast paragraph</p></body>、</正規表現トークンは以下にマッチします。</で</p>。しかし、bは失敗します。p。その時点で、正規表現エンジンはバックトラックし、遅延ドットを展開して以下を含めます。</p>。正規表現エンジンはまだアトミックグループを離れていないため、グループ内で自由にバックトラックできます。いったん</body>がマッチし、正規表現エンジンがアトミックグループを離れると、遅延ドットのバックトラック位置が破棄されます。その後、それ以上展開できなくなります。
基本的に、私たちが行ったことは、繰り返し発生する正規表現トークン(HTMLコンテンツにマッチする遅延ドット)を、その後に続く非繰り返しの正規表現トークン(リテラルのHTMLタグ)にバインドすることです。正規表現内のHTMLタグの間には、HTMLタグを含むあらゆるものが現れる可能性があるため、区切りとなるHTMLタグがHTMLコンテンツとしてマッチされるのを防ぐために、遅延ドットの代わりに否定文字クラスを使用することはできません。しかし、各遅延ドットとその後に続くHTMLタグをアトミックグループに組み合わせることで、同じ結果を達成することができました。HTMLタグがマッチするとすぐに、遅延ドットのマッチはロックされます。これにより、遅延ドットが、正規表現内のリテラルHTMLタグでマッチされるべきHTMLタグにマッチすることがなくなるようにします。
| クイック スタート | チュートリアル | ツール & 言語 | 例 | リファレンス | 書籍 レビュー |
| 正規表現の例 | 数値範囲 | 浮動小数点数 | メールアドレス | IPアドレス | 有効な日付 | 数値の日付をテキストに | クレジットカード番号 | 完全な行のマッチング | 重複行の削除 | プログラミング | 2つの近い単語 |
| 壊滅的なバックトラック | 過剰な繰り返し | サービス拒否 | すべてをオプションにする | 繰り返しキャプチャグループ | Unicodeと8ビットの混在 |
ページURL: https://regular-expressions.dokyumento.jp/catastrophic.html
ページの最終更新日: 2021年8月15日
サイトの最終更新日: 2024年3月15日
Copyright © 2003-2024 Jan Goyvaerts. All rights reserved.